


One of Google’s main competitors when it comes to its deep learning models comes from the SEE region. The Croatian startup airt develops a deep learning platform to help companies predict their end customers’ behavior.
The deep tech startup was founded three years ago, in 2019 as a consulting project in abank. After realizing the potential of its solution, the startup quickly grew into building a full-blown AI platform, airt’s CEO and cofounder Hajdi Cenan explains.
While her background is mainly in sales and marketing, and she describes herself a newcomer in the tech world, airt’s other co-founder Davor Runje is a computer engineer and a serial entrepreneur. He co-founded PlayMedia Systems in 1997 and launched the AMP MP3 technology on the global market.
“I’ve already changed two industries – media and digital marketing – before entering the world of tech, but I say that is what helps me translate this technology into the language of regular people,” Cenan tells The Recursive.
When it comes to the idea behind airt, according to her, while many companies sit on large amounts of data, most still aren’t successful when it comes to implementing AI across the entire organization, largely due to a lack of available expertise.
“We, on the other hand, have spent almost three years deep-diving into and solving the problem of predicting customer behavior through event-based data. We built a fully managed and fully automated cloud-native platform that uses deep learning to profile and predict end customers’ behavior,” Cenan tells The Recursive.
Airt’s platform can be used to predict any combination of events and non-events, thus making it a one-stop solution for numerous business applications, such as propensity to buy, up and cross-sell, churn, best time and channel to send a message, and so on.
“Furthermore, the platform is low code, making it possible for even non-data scientists, (such as IT engineers) to implement it and run it on company data,” Cenan points out.
Competing with giants such as Google and IBM
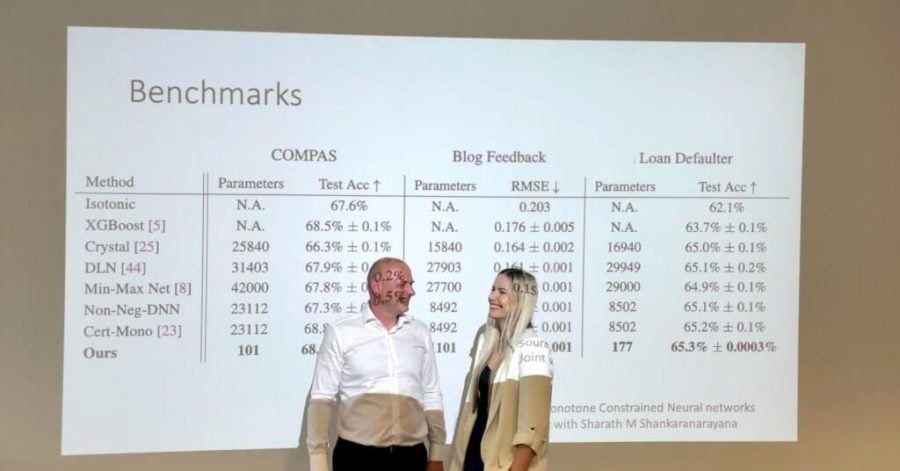
The young Croatian startup has so far filed two patent applications; the first one is benchmarked against a state-of-the-art model from IBM and better, while the second is benchmarked against a state-of-the-art model from Google and better, Cenan explains.
“It took us quite some time and lots of research and development to build a solution that can really deliver, but we now have a fully automated end-to-end platform capable of scaling to 100k models per month and performing 100+ million predictions,” she tells The Recursive.
Since airt’s techniques use orders of magnitude fewer parameters than competing solutions, they are very energy efficient and cost-efficient, Cenan emphasizes.
“Besides cost efficiency and accuracy, our solution is domain and problem agnostic, as long as the problem can be described in terms of probabilities of an event happening or not, allowing us to automate and scale it out across a wide range of industries and businesses,” she points out.
The startup is now actively looking for opportunities to partner with platforms serving data collection and client communications.
“We believe that tightly integrating data collection, prediction, and communication, in one seamless solution, would enable us to serve not just the high-end of the market such as banks, but also the entire long tail of companies using digital channels for conducting their business. As for financing, we’ve done the angel round, and are now raising a seed round to support selling and scaling,” Cenan says.
The future of deep learning technology
For Cenan, one of the big problems of deep learning is that it’s still a black box and it’s not quite clear how exactly the algorithms derive the conclusions and recommendations used for business decisions.
“In other words, even if one knows which parameters and how their movement (increase or decrease) should influence the end result, there is no guarantee in deep learning that it will actually happen in that way,” Cenan says.
That is why many businesses are still reluctant to use deep learning, despite its superior results, as they need to be able to explain the end decision.
To help improve the solutions that are already out there, airt is now working on two important topics, and one of them is making deep learning models work better with smaller dataset sizes.
“In computer vision and NLP (natural language processing), that is not such an issue because data is overwhelming and generating more of it is not a big deal. However, businesses have what they have, and getting more data is expensive in terms of both direct cost and time, both being scarce. Our research is focused on scaling down deep learning techniques in the sense of requiring less data, and monotonic neural networks are one good example of it. Introducing structural biases such as these allows us to build smaller models with high accuracy, but with much less data,” Cenan tells The Recursive.
The second important issue is related to using algorithms for making important decisions in society – for example, access to an affordable loan has life-changing consequences.
“We are increasingly outsourcing such decisions to predictive models without fully understanding the consequences. We need to build trustworthy models to be able to build a better society and we are working hard to get there,” Cenan concludes.




